Optimizing Workflows in Distributed Systems
A Case Study for the Lleida Population Cancer Registry
Whoami
- Industrial PhD Student at GFT
- Working on industrial implementations of federated learning

Problem Statement
Goal
Analyze associations: Medication and cancer type effects on patient survival (protective or harmful).
Challenge
Analyzing 79,931 combinations of medications and cancer types from 2007-2019.
Inital Approach
A single machine would require 61 days to complete this analysis, with each combination consuming 66 seconds.
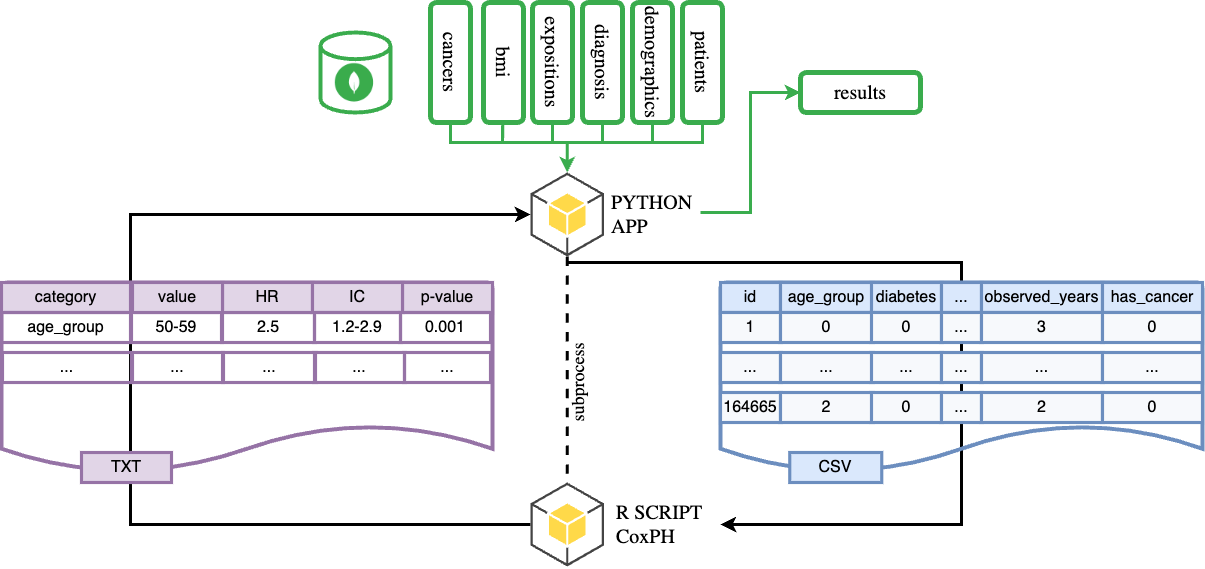
Data schema impact
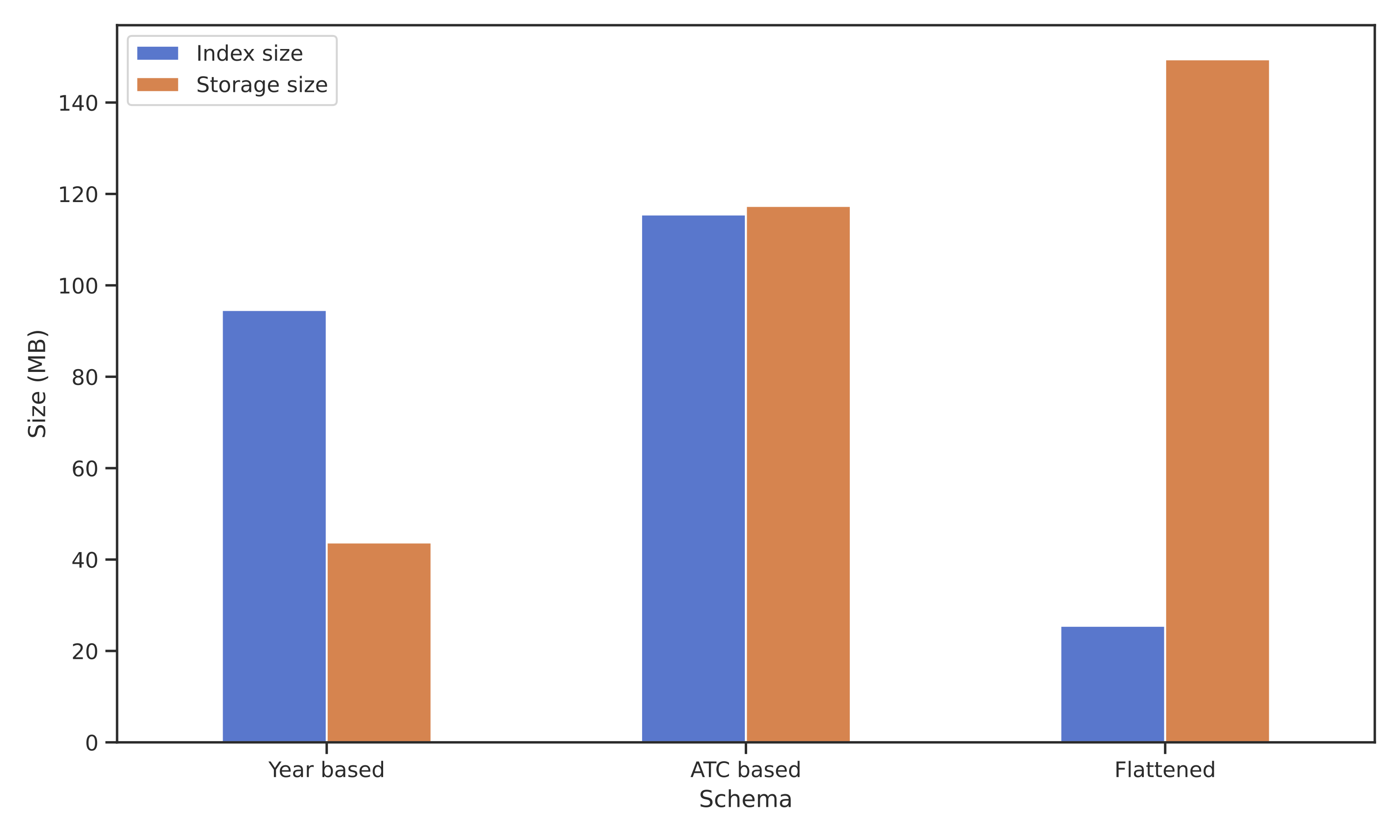
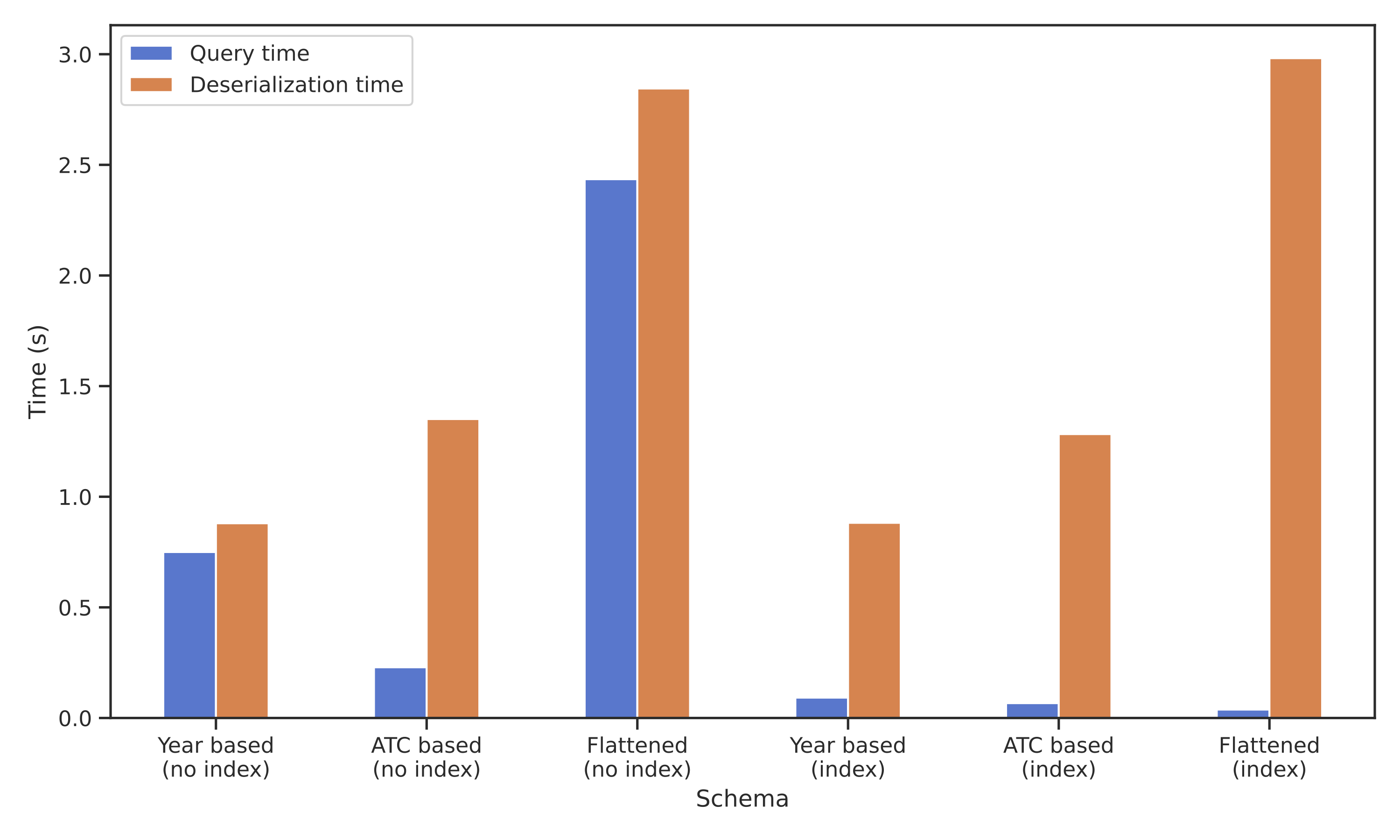
Observation
Proposed solutions reduce query time (at the cost of disk space for indexes). However, deserialization time increases across all proposals.
Next Steps
How can we simultaneously minimize deserialization time and reduce query execution?
Deserialization
Findings
- PyMongo returns Python dictionaries → slow for large result sets
- PyMongoArrow improves typing, but still memory-heavy
- Optimal performance requires columnar layout with primitive types
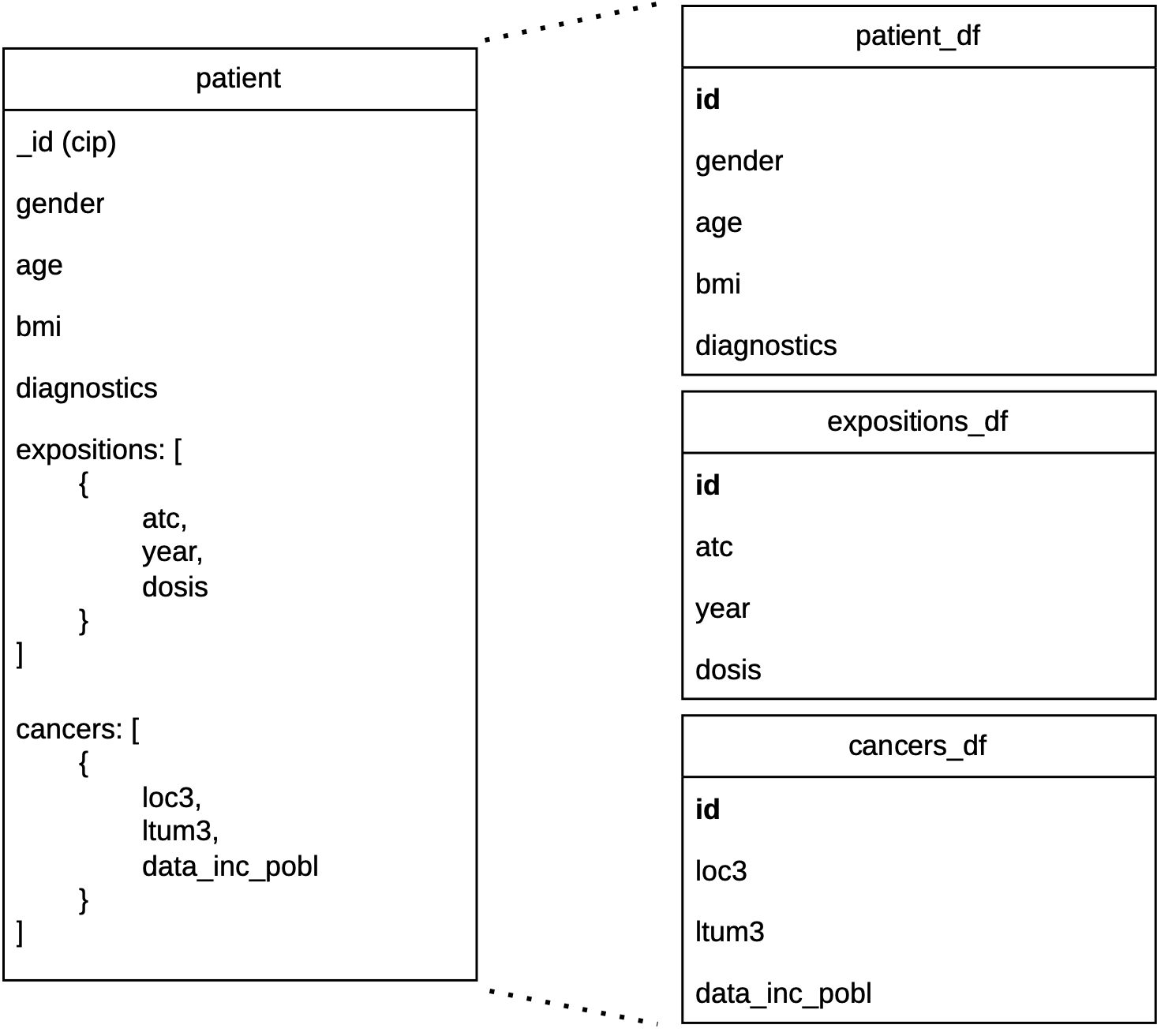
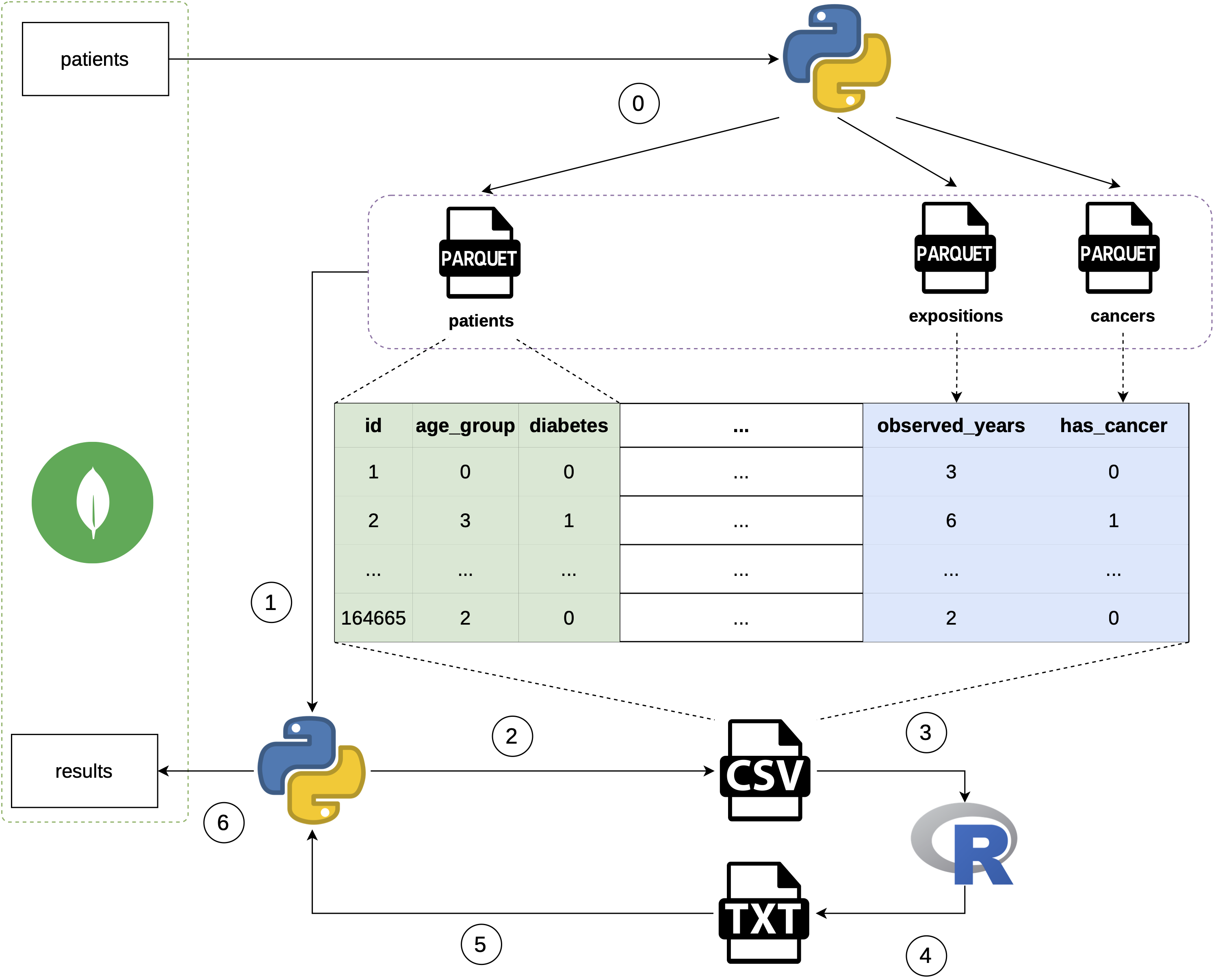
Solution
- Solution: split into 3 DataFrames:
patients,expositions,cancers
Upgrade
Mechanism
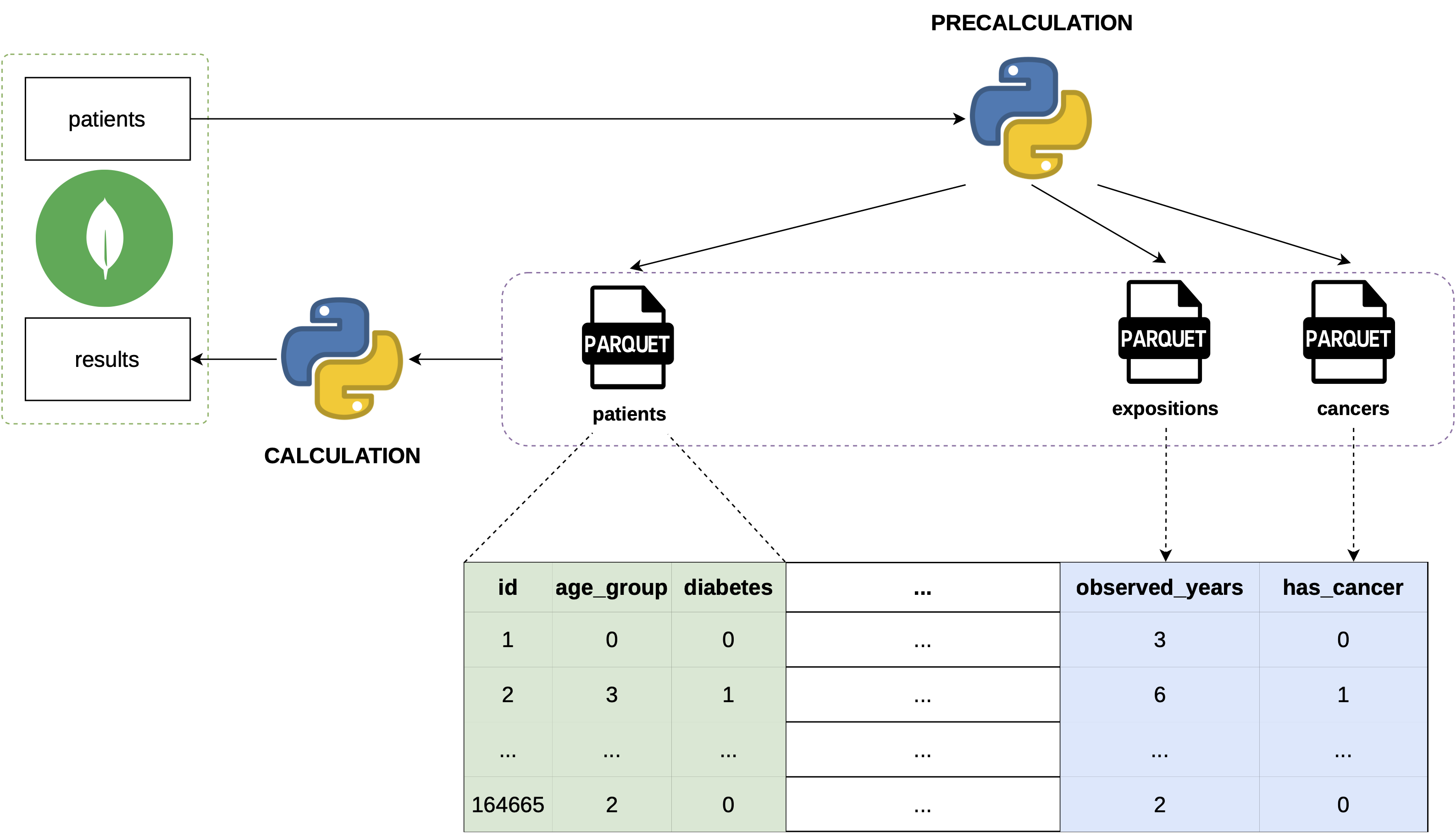
- Precalculate Dataframes
- Read the Dataframes
- CSV generation with features and the event column
- CSV reading and data preprocessing
- COXPH analysis (using a file as stdout)
- Read and parse the results
- Save structured results for later queries
Improvements
- Query-driven -> Reduce time to get data.
- Precalculate shared data -> Avoid repeated queries.
- Use Parquet files -> Efficient storage and fast access.
Eliminating Communications
Problem
Disk I/O for inter-process communication (IPC) with R is a significant bottleneck.
Results
We reduce the processing time from 66 seconds to less than 1 second per combination.
| Function | Time (ms) |
|---|---|
get_cox_df |
52 |
calculate_cox_analysis |
776 |
parse_cox_analysis |
22 |
save_results |
21 |
Task distribution
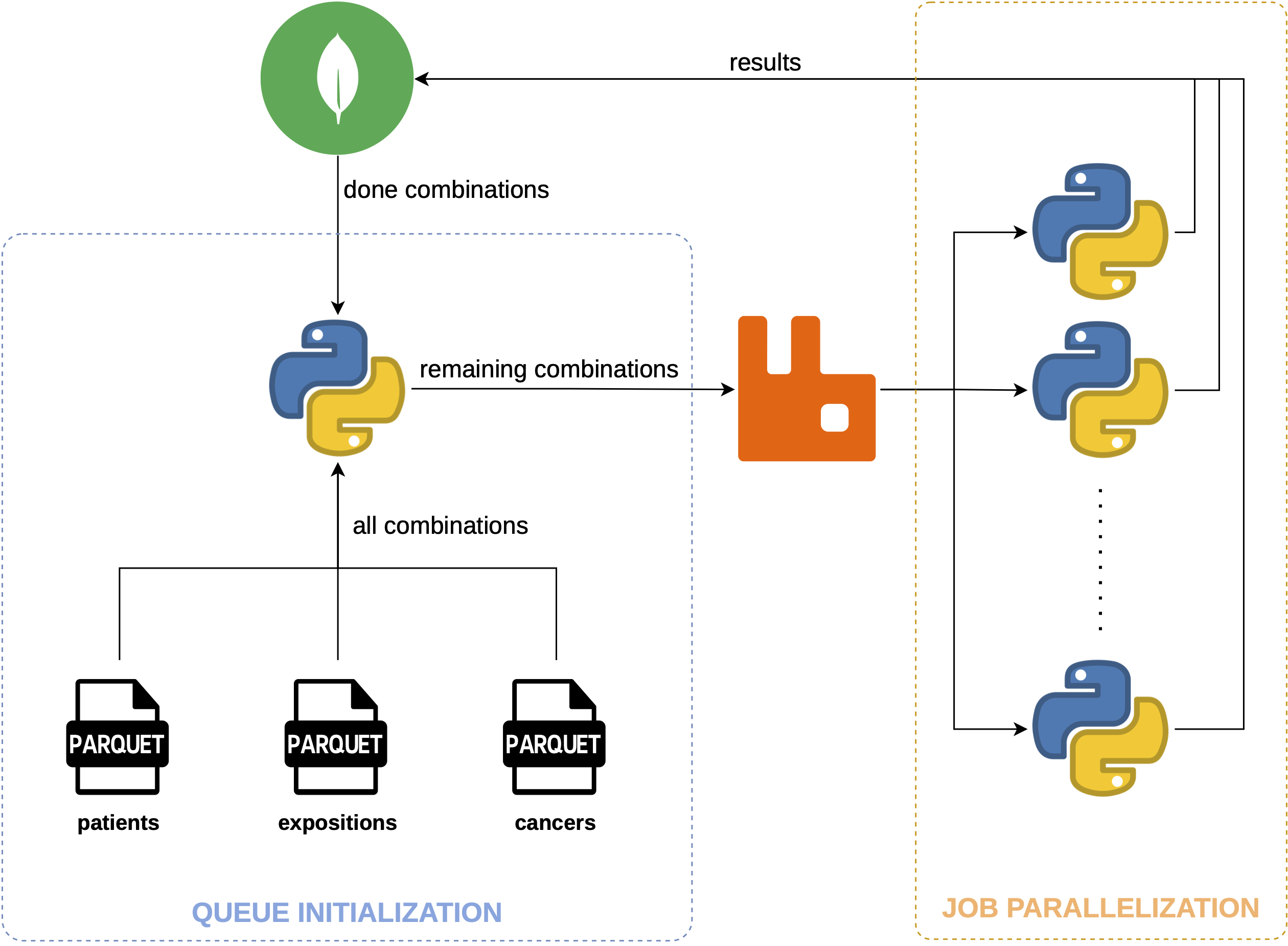
Architecture
- Task independence: Each task is a particular combination of medication and cancer type -> can be processed independently.
- Task Queue: Distributes tasks to worker processes (rabbitmq).
- Worker Processes: Can be configured to run on different machines, allowing for distributed computing.
- Task Management: Each worker fetches tasks from the queue, processes them, and returns results to the main process.